|
 Los
modelos de inteligencia artificial están revolucionando las
herramientas de diagnóstico por imágenes, diagnóstico
anatomopatológico, interpretación de estudios de laboratorio, y
hasta el mismo diagnóstico clínico. En la enorme mayoría de los
estudios los algoritmos se acercan o superan claramente al
médico más avezado en dar con la causa de la anomalía observada.
Los sistemas se usan también para desarrollar herramientas de
pronóstico, donde también hay enormes sorpresas. Y no se queda
atrás el uso de algoritmos para llevar adelante investigaciones;
identificar potenciales tratamientos, definir factores de
riesgo, en incluso profundizar en sutiles anomalías antes no
advertidas, asociadas a enfermedades ya conocidas. Todo esto
crea un enorme desafío para la medicina como ciencia. El lugar
que ocupará la explicación causal en los próximos
descubrimientos, las razones de nuestra conducta clínica, los
motivos que nos obliguen a tomar tal o cual decisión de
relevancia para el paciente, podrían extraviarse entre los
intrincados parámetros, nodos, y demás funciones que componen
las redes neuronales y otros algoritmos propios de las técnicas
de inteligencia artificial. El problema no es menor y recibe el
nombre de “explicabilidad” de los modelos. La cuestión de la
explicabilidad de los modelos resulta un ataque directo al
corazón de la inferencia científica que ha especificado el
desarrollo de la medicina durante siglos. Los
modelos de inteligencia artificial están revolucionando las
herramientas de diagnóstico por imágenes, diagnóstico
anatomopatológico, interpretación de estudios de laboratorio, y
hasta el mismo diagnóstico clínico. En la enorme mayoría de los
estudios los algoritmos se acercan o superan claramente al
médico más avezado en dar con la causa de la anomalía observada.
Los sistemas se usan también para desarrollar herramientas de
pronóstico, donde también hay enormes sorpresas. Y no se queda
atrás el uso de algoritmos para llevar adelante investigaciones;
identificar potenciales tratamientos, definir factores de
riesgo, en incluso profundizar en sutiles anomalías antes no
advertidas, asociadas a enfermedades ya conocidas. Todo esto
crea un enorme desafío para la medicina como ciencia. El lugar
que ocupará la explicación causal en los próximos
descubrimientos, las razones de nuestra conducta clínica, los
motivos que nos obliguen a tomar tal o cual decisión de
relevancia para el paciente, podrían extraviarse entre los
intrincados parámetros, nodos, y demás funciones que componen
las redes neuronales y otros algoritmos propios de las técnicas
de inteligencia artificial. El problema no es menor y recibe el
nombre de “explicabilidad” de los modelos. La cuestión de la
explicabilidad de los modelos resulta un ataque directo al
corazón de la inferencia científica que ha especificado el
desarrollo de la medicina durante siglos.
¿Cómo funcionan los modelos de
inteligencia artificial?
Los modelos de inteligencia artificial y aprendizaje automático
demuestran gran habilidad para predecir el comportamiento de
complejas dependencias, es decir para predecir los valores de
una o múltiples variables dependientes, generando predicciones
muy precisas respecto de los valores que adoptarán estas
variables del resultado de interés en cualquiera proceso que se
evalúe.
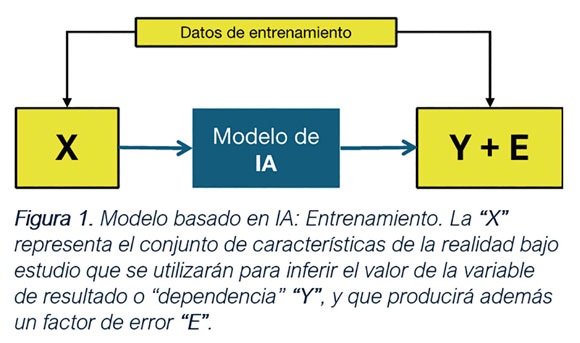
Un modelo de inteligencia
artificial (IA) consiste en un
conjunto de reglas, algoritmos y
parámetros que se utilizan para
aprender a partir de datos, y
desde allí tomar decisiones o
realizar tareas. Los modelos de
IA se basan en la idea de que
los datos pueden ser utilizados
para entrenar a un modelo
estadístico para que aprenda a
reconocer patrones en la
información y de esta forma
hacer predicciones.
En la figura (figura 1) se puede
ver un diagrama básico de cómo
funciona un modelo de IA. El
modelo consiste en un conjunto
de herramientas estadísticas que
en el caso de los grandes
modelos generativos son redes
neuronales artificiales, que
junto a otros algoritmos
accesorios producen una
estimación sobre una pregunta.
La pregunta será siempre una
clasificación, como cuando
deseamos saber si el paciente es
o no diabético, o un grado de
expresión de una variable; por
ejemplo, cuando preguntamos por
el riesgo de mortalidad a seis
meses de un caso de cáncer de
esófago.
Similar a como podría ocurrir
con una regresión logística o
una regresión simple, los
algoritmos estadísticos reciben
una serie de valores de las
variables de entrada o
independientes, denominadas
genéricamente “X”, y producen,
gracias a los parámetros que
gobiernan su funcionamiento, una
estimación para la o las
variables de salida o
dependientes agrupadas en “Y”.
Los parámetros que regulan su
funcionamiento son cantidades
que determinan cómo funciona el
sistema de predicción. En el
caso de la regresión simple, por
ejemplo, los mismos se llaman
coeficientes de la regresión y
definen los dos puntos de la
recta que se utilizará para
predecir un valor de la variable
de resultado Y para cada valor
de ingreso de X. En el caso de
las redes neuronales
artificiales los parámetros que
gobiernan su funcionamiento son
bastante más complejos y se
denominan “pesos”; pero el
principio es el mismo.
A modo de ejemplo entonces, el
algoritmo recibe la información
de que las variables de
temperatura corporal,
radiografía de tórax, y
expectoración, dan valores de
“fiebre”, “opacidad”, y “esputo
purulento” respectivamente. El
algoritmo produce entonces el
valor neumonía para la variable
de resultado, que era
“diagnóstico más probable”.
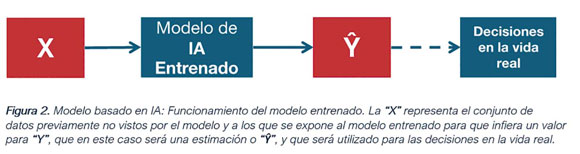
En el proceso habrá errores, que serán minimizados modificando
los valores de los parámetros del modelo durante el proceso de
“aprendizaje automático”. Al cabo de este ciclo el modelo se
considera “entrenado”, que es cuando su error de predicción es
mínimo. A partir de allí el mismo puede ser utilizado para
realizar predicciones sobre la variable de resultado “Y”, siendo
expuesto a los valores de las variables predictoras agrupadas en
“X” (figura 2) que nunca había visto antes. Así separará a los
pacientes en neumonía y no neumonía en un proceso de
“inferencia” estadística.
Recapitulando entonces, un modelo de IA consta de datos de
entrada y un complejo proceso de procesamiento de datos. El
modelo prepara los datos de entrada para que sean utilizados por
la red neuronal. Esto puede incluir la limpieza de datos, su
normalización, trans- formaciones y demás. La red neuronal luego
será el corazón del modelo de IA. Consiste en un conjunto de
capas de cálculos estadísticos denominados redes neuronales
artificiales que se conectan entre sí para procesar los datos de
entrada. Las capas de neuronas artificiales extraen
características de los datos y las envían de una a otra capa
creando una función matemática que terminará expresará los
patrones reconocidos. Estos patrones encontrados en la
información de entrada se utilizarán para inferir los
resultados, es decir los valores de la variable dependiente de
interés, “Y”. El modelo aprende a partir de los datos de
entrada, y lo hará de manera supervisada, no supervisada, o
reforzada. El conjunto de funciones matemáticas que componen al
modelo están regidas por parámetros, que son los valores que se
ajustan durante el proceso de aprendizaje para que el modelo
produzca el menor error de predicción posible a partir de los
datos de entrada. Los valores de los parámetros del modelo serán
ajustados mediante técnicas de optimización como el gradiente
descendente y otras. La salida es el resultado final del modelo
de IA, que puede ser una predicción, una clasificación (es el
caso de nuestro ejemplo, en neumonía sí o no), una
recomendación, etc. Los modelos de IA se entrenan con datos
conocidos y se validan mediante la comparación de sus
predicciones con datos nuevos o no vistos, ajustando los modelos
para mejorar su precisión.
Inferencia de la Inteligencia
Artificial
Correctamente se ha definido a la IA como un “proceso de
automatización de la inferencia”. Recordemos que la inferencia
es el proceso lógico por el cual, a partir de datos de la
realidad, siempre limitados, se descubre una relación de los
mismos con una ley general u otro proceso más general que hará
que, dadas idénticas circunstancias, se generen siempre valores
similares (probabilísticamente similares) a los observados. Por
ejemplo, a partir de la observación de la presión arterial en
innumerables pacientes se descubre (por inferencia) que la
presión arterial diastólica normal de un ser humano promedio se
encuentra entre los 70 y 90 milímetros de mercurio.
Los modelos de IA utilizan algoritmos de aprendizaje automático
para hacer predicciones o decisiones basadas en datos. Los
algoritmos identifican los patrones y relaciones dentro de
grandes conjuntos de datos, e infieren leyes o patrones que
usará luego para predecir resultados futuros o desconocidos.

La inferencia lógica es el proceso mental básico detrás de todo
diagnóstico clínico, igual que detrás de todo descubrimiento
científico. Se infiere un diagnóstico a partir de los datos de
una biopsia, se infiere la utilidad de un betabloqueante a
partir de los datos de un ensayo clínico, o se infiere la
fisiología respiratoria a partir de los datos de variaciones de
presión de la vía aérea y del espacio pleural. Sucede entonces
que en el caso de la IA, el sistema infiere por nosotros, y dada
la complejidad del proceso, muchas veces siquiera podremos
entender cómo llegó el algoritmo a la conclusión que llegó,
aunque si sabremos que la misma es correcta la enorme mayoría de
las veces. La IA es muy eficaz, pero le resulta casi imposible
decirnos cómo acertó en el blanco. No deja espacio a la
inferencia lógica, propia de la ciencia.
Interpretabilidad de modelos
Sucede que además de estar interesados en los valores que
adoptaron las variables dependientes que nos interesan en un
determinado proceso, muchas veces los médicos necesitamos o
simplemente deseamos entender la propia dinámica del proceso que
genera esos datos. Vale decir, queremos conocer los mecanismos
intermedios que en definitiva se encuentra detrás de las
predicciones realizadas por los algoritmos. Esto equivale a
decir que los médicos estamos interesados en los mecanismos que
producen los fenómenos que observamos. Queremos saber cómo se
realizó la inferencia. Sin embargo, en el caso de la IA, la
realidad es que la compleja naturaleza no lineal de muchos
modelos de aprendizaje automático que se están desarrollando en
diferentes áreas de la salud los vuelve opacos y prácticamente
imposibles de comprender para el humano que los entrena. La
capacidad de entender y explicar cómo los modelos de IA llegan a
sus conclusiones, no obstante, resulta crucial para generar
confianza y validar resultados, especialmente en áreas sensibles
como la salud. Entramos entonces en una paradoja; la IA, que
automatiza la inferencia estadística, podría aniquilar la
inferencia lógica del médico o del científico que la utiliza.
La explicabilidad de los modelos, es decir la posibilidad de entender los caminos por los cuales el algoritmo llega a sus
conclusiones, daría transparencia, interpretabilidad, y
responsabilidad ética al uso de la IA en salud.
En cuanto a la trasparencia, es crucial que los modelos de IA
sean interpretables y comprensibles para que usuarios y
desarrolladores puedan comprender cómo se toman las decisiones.
Cómo se llegó a una decisión que seguramente será correcta, pero
cuyo origen termina siendo misterioso. La capacidad de los
modelos de IA para proporcionar explicaciones claras y
entendibles sobre sus predicciones y decisiones sería esencial
para generar confianza en los usuarios y garantizar su correcto
uso. Y la explicabilidad de los mismos sería indispensable para
cumplir con normativas y estándares éticos, asegurando que las
decisiones automatizadas sean justas, responsables y no
discriminatorias. Todo esto es imposible si nadie entiende cómo
funcionó la máquina al ser expuesta a determinados datos.
Mínimamente en los modelos de inteligencia artificial que se
publican, debería quedar claro cuáles propiedades del proceso
aleatorio que genera los datos son computadas, y cuál es el
tratamiento que se ha hecho de la varianza y la incertidumbre en
los mismos. Y aún no hemos llegado al punto más delicado de la
cuestión, cual es la relación de causalidad. El porqué de las
cosas lo descubrimos al advertir relaciones de causalidad entre
fenómenos medidos. Diferenciar entre relaciones causales y meras
correlaciones es esencial tanto en la inferencia científica como
en las aplicaciones de IA, particularmente en el campo médico
donde las intervenciones tienen consecuencias directas.
Causalidad vs correlación:
La propia naturaleza de la pesquisa médica, sea al momento del
diagnóstico como en el proceso de investigación científica, hace
que los profesionales estemos interesados no solo en la
asociación entre valores de variables de interés, sino en
conocer la causa de aquello que observamos. Por ejemplo, lesión
aterosclerótica e infarto se asocian, pero pretendemos
comprender cómo se establece causalidad. Todos los médicos
tenemos la experiencia de la insuficiencia de las asociaciones
para deducir causalidad. Por ejemplo, ciertos síntomas pueden
asociarse con una enfermedad, la cual, al ser tratados aquellos,
no necesariamente se verá afectada. Dicho esto, ganar
profundidad en cuanto a los efectos de una intervención podría
requerir conocimiento causal, es decir mecanicístico, y
experimentos controlados para comparar por ejemplo tratamientos.
La distinción entre causalidad y correlación es fundamental en
el ámbito médico. Para desarrollar tratamientos efectivos, los
médicos necesitan entender qué factores causan realmente una
enfermedad o condición, no solo cuáles están asociados con ella.
Una correlación puede llevar a intervenciones ineficaces o
incluso perjudiciales si se confunde con una relación causal.
Ahora bien, la asociación estadística, base del funcionamiento
de la IA, de ninguna manera demuestra causalidad; a lo sumo la
sugiere. Identificar las verdaderas causas de las enfermedades
permite desarrollar estrategias de prevención más efectivas.
Comprender las relaciones causales permite a los médicos adaptar
los tratamientos a las características específicas de cada
paciente, considerando cómo diferentes factores interactúan para
causar o exacerbar una condición. Esta particularización del
accionar profesional es opuesta a la estandarización que puede
ofrecer la IA. Los ejemplos podrían continuarse.
Lo cierto es que un modelo basado en IA que sea sumamente eficaz
para predecir el evento de interés en base a millones de datos,
pero que no pueda dar cuenta de las asociaciones que
específicamente fueron utilizadas para llegar a la conclusión,
es decir un modelo no explicable, será un serio impedimento para
estableces vínculos de causalidad, indispensables para la
comprensión profunda de los hechos.
Necesidad de modelos que
expliquen la causalidad en medicina
Los modelos de inteligencia artificial aplicados a las ciencias
de la salud, por lo menos, necesitan entonces poder ser
interpretados de alguna forma. El inconveniente surge cuando la
exigencia de explicabilidad podría restar eficacia al sistema de
inteligencia artificial en operaciones. Justamente el
autoaprendizaje y la complejidad matemática inherente a las
redes neuronales recurrentes y el proceso de aprendizaje
profundo, permiten a estas ecuaciones modelar complejísimas
distribuciones de los datos que surgen de las observaciones de
la realidad. Pretender traducir estos modelos a una forma
entendible por el entrenador de estos, o el eventual usuario
terminaría conduciendo necesariamente a su simplificación y
evidentemente a su pérdida de capacidad predictiva. Para darnos
una idea de lo que hablamos, baste decir que un punto en el
espacio podría ser ubicable por tres valores correspondientes a
tres parámetros. Más allá de aquí, resulta inimaginable para
nuestra mente. Los modelos de inteligencia artificial pueden
utilizar para ubicar a un punto, es decir para definir su
posición, mil millones de coordenadas, o el doble. Los grandes
modelos generativos caracterizan la información usando
hiperespacios de mil o dos mil millones de dimensiones.
Las soluciones que se están buscando al dilema son varias. Una
es la incorporación de la inferencia causal en los propios
algoritmos. Se necesitan modelos estadísticos y de IA que no
solo identifiquen correlaciones, sino que puedan inferir
relaciones causales a partir de datos observacionales, ensayos
clínicos, estudios longitudinales, información mecanicística, y
evidencia previa. A estos fines los modelos están integrando
diferentes técnicas capaces de explicar cómo se llega al
resultado arrojado por los modelos. También se está ensayando el
uso de diagramas causales que ayudarán a visualizar y analizar
relaciones causales complejas en sistemas biológicos y médicos.
Los modelos, en un futuro cercano, podrán simular escenarios “what-if”
(qué sucedería si...) para predecir los efectos de
intervenciones médicas, lo cual demandará alguna forma de
entendimiento causal del sistema bajo análisis. También se busca
desarrollar modelos que puedan identificar y cuantificar los
mecanismos intermedios a través de los cuales una causa produce
su efecto. Los modelos, además, están incorporando métodos para
capturar cómo los efectos causales pueden variar entre
diferentes subgrupos de pacientes, o agrupaciones de datos.
El desarrollo de modelos causales en medicina combina
estadística avanzada, aprendizaje automático y conocimiento
médico experto. La integración de conocimiento experto en los
modelos de IA consiste en combinar el aprendizaje automático con
el conocimiento humano especializado para mejorar la precisión y
relevancia de los modelos, especialmente en campos como la salud
donde el contexto y la experiencia son críticos. Entender mejor
las relaciones causales entre los factores que influyen en las
enfermedades revolucionará la práctica médica, y enriquecerá la
toma de decisiones informadas.
Tan importante como esclarecer los mecanismos de inferencia, es
decir las razones de los resultados, así como las relaciones
causales, es la explicitación de los grados de incertidumbre que
se incluyen en las respuestas. Un modelo generativo puede ser
consultado por un diagnóstico. Su devolución debería incluir
medidas de incertidumbre, así como distribuciones
probabilísticas de los diferentes resultados. De esta manera la
devolución será más realista, pues siempre existe algún nivel de
incertidumbre, ya sea fenomenológica como epistemológica.
Las técnicas de inferencia basadas en IA tienen un poder
formidable. Ahora bien, los resultados no están exentos de tres
características de la realidad que en definitiva genera las
observaciones sobre las cuales se concluye. Primero, la realidad
produce valores intrínsecamente variables, derivados de la
aleatoriedad propia de la física que produce lo que observamos.
Segundo, la realidad no es absolutamente variable ni
absolutamente aleatoria, sino que en ella existen regularidades
propias de la naturaleza, las que hacen posibles los patrones
indispensables para cualquier proceso de inferencia. Finalmente,
la mente humana no siempre está convencida o cierta. La certeza
ocurre solo en nuestra mente. Es a nosotros a quienes debe
convencernos la inferencia estadística que realiza el modelo.
Finalmente es la mente humana la única capaz de inferir en
términos lógicos. Y, paradójicamente, nos es de gran ayuda para
desarrollar mayores niveles de certeza frente a algo
tremendamente variable como es la salud, conocer los niveles de
incertidumbre con que trabaja la estadística, alma del sistema
de inteligencia artificial
| (*) Médico y Doctor en Medicina /
Ex - titular del PAMI. |
|





















